
The Mechanics of AI Memory: What Every Engineer Should Know About Tokens and Context Windows
In today’s AI-driven world, technical professionals are expected to not just use AI—but to understand it. This article breaks down two essential concepts you must know to work effectively with large language models (LLMs): tokens and context windows.
You’ll learn:
- How AI splits and processes text using tokens
- Why context window size directly impacts performance, cost, and memory
- Practical tips for optimizing prompts, documents, and applications for maximum efficiency
- Strategic considerations when choosing between AI platforms like Claude, ChatGPT, Copilot, and Gemini
Whether you’re tuning prompts, integrating APIs, or guiding AI adoption in your organization, mastering these fundamentals will help you get better results, lower costs, and lead more impactful AI projects.
💡 IMPORTANT TIP: While many examples in this article reference Claude, the principles, concepts, and optimization strategies apply similarly to all AI chat interfaces including ChatGPT, Microsoft Copilot, Google Gemini, and others. The specific token limits and pricing models may vary, but the fundamental mechanics of how tokens and context windows function remain consistent across platforms.
What Are Tokens?
Tokens are the fundamental units of text that AI models like Claude, ChatGPT, and Copilot process. Each AI system breaks down text into smaller pieces called tokens through a process called “tokenization.” These tokens can represent words, partial words, characters, or even punctuation.
The Mechanics of Tokenization
When you interact with an AI platform, your inputs and its responses are measured in these tokens. Here’s how tokenization works:
- Breaking Down Text: The AI splits text into manageable chunks based on common patterns and frequencies in language
- Converting to Numbers: Each token is assigned a numerical ID that the AI can process
- Processing: The AI performs calculations on these numerical representations
- Converting Back: For output, the process is reversed to generate human-readable text
Key Token Characteristics
- Size relationship: In English text, one token typically equals about 0.75 words or roughly 4 characters
- Language variations: Non-English languages often require more tokens per word (e.g., Chinese characters may be more token-efficient, while languages with complex words like German may require more tokens)
- Special tokens: Programming code, mathematical formulas, and specialized technical content can tokenize differently than natural language
- Bidirectional counting: Both your inputs (prompts) and the AI’s outputs (responses) consume tokens
- Billing implications: Most AI providers charge based on token usage, making token efficiency a business consideration
💡 TIP: To optimize token usage in prompts, be concise and specific. For example, instead of “Please write a comprehensive and detailed analysis of this topic covering all aspects and considerations,” try “Analyze this topic focusing on key aspects.” The shorter version could save 10-15 tokens while achieving the same result.
Got it — you want a compact, clean section that tells the full story without feeling overwhelming.
I’ll combine the explanation, the real-world example, and the before/after optimization into one tight, coaching-style section.
Here’s the fully condensed, professional version:
How AI Splits and Processes Text Using Tokens (with Real Example)
Before an AI like Claude or ChatGPT can understand your input, it first breaks your text into smaller pieces called tokens. Here’s how it works:
- Splitting: Text is divided into words, parts of words, punctuation, or symbols.
- Encoding: Each token is mapped to a unique number the AI understands.
- Processing: The AI analyzes these tokens to predict and generate responses.
- Rebuilding: The AI translates its numeric results back into readable text.
Real-World Example
Here’s a real input:
Original Sentence:
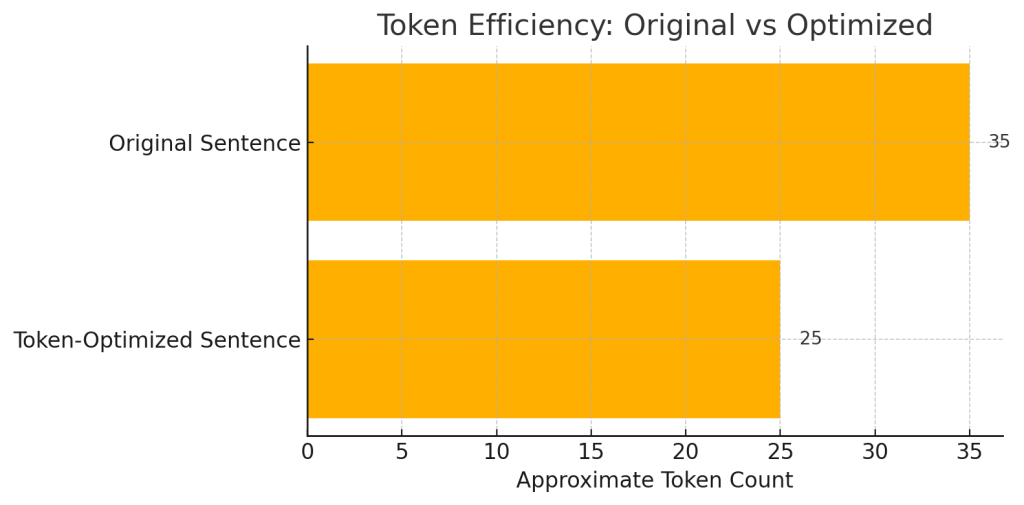
“Please show me what I should include in my sales plan; consider best practices. This will be used to create a Sales Blueprint for Sales professionals in my business to follow.”
Tokenization:
This breaks down into ~34–36 tokens — including every small word, punctuation mark, and repetition.
| Text Fragment | Token |
|---|---|
| Please | Please |
| show | show |
| me | me |
| … | … |
| follow | follow |
| . | . |
➡️ Every word or symbol counts! Even “please,” “to,” “;” and “.” are full tokens. Words are even broken down further. A simplistic way to look at tokenization is to think of each syllable of a word as a token. This will give you a more realistic token count.
Optimized Version
We can express the same idea more efficiently:
Token-Optimized Sentence:
“List best practices to include in a Sales Blueprint for my team’s sales plan.”
| Original | Optimized | |
|---|---|---|
| Approx. Tokens | 34–36 | 24–26 |
| Style | Friendly, detailed | Direct, efficient |
| Use Case | Collaboration or creative tasks | High-volume processing or cost-saving |
💡 Coaching Tip
Clarity first, efficiency second:
If tone matters—like in brainstorming or creative work—being polite and conversational can create better engagement.
If you need speed and cost savings—like for processing lots of documents—focus on tight, directive language.
Even saving 10 tokens here or there adds up fast across long documents, API calls, or ongoing AI interactions.
Small edits → Big wins over time.
When you start creating your own bots this will matter, until then it is likely less important.
Context Windows: Why Size Matters
The context window represents how much information an AI model can “see” and remember during a conversation. This technical limitation affects several aspects of AI performance:
Technical Implementation
The context window implementation varies by AI model, but generally:
- Storage mechanism: The AI maintains a buffer of recent tokens it has processed
- Position awareness: Each token knows its position relative to others in the sequence
- Attention mechanism: The AI’s neural architecture applies varying levels of “attention” to different tokens in the window
- Memory management: When the window fills up, older tokens are typically discarded in a first-in, first-out manner
💡 TIP: For long-running projects, periodically create summary checkpoints. For example: “Based on our conversation so far, here’s what we’ve established: [key points]… Now let’s continue with [next step].” This technique preserves critical context while allowing you to start a fresh conversation that consumes fewer tokens.
Performance Impact of Context Windows
Memory and Performance Tradeoffs
Larger context windows require more computational resources, which directly impacts:
- Response speed: Larger windows require more calculations, potentially increasing latency
- Processing costs: More tokens mean more computations, increasing power consumption and operational expenses
- Memory requirements: Storing larger windows demands more RAM in the hosting systems
- Lost in the middle phenomenon: Some AI models struggle to recall information in the middle of very large context windows
This last point is particularly important for business users. The “lost in the middle” phenomenon refers to how some AI models perform poorly when retrieving information that appears in the middle of a long document. Claude and newer models have made significant improvements in addressing this limitation, but it remains a consideration for very long contexts.
💡 TIP: When uploading large documents for analysis, place the most critical information at the beginning or end of the document where possible, as these positions are less susceptible to the “lost in the middle” effect. Alternatively, break large documents into logical sections and upload them separately.
Artifacts vs. Chat: Different Token Economies
When using Claude’s artifact creation feature, the token economy works differently than in regular chat:
- Chat mode: In chat, the entire conversation history is processed with each new message, meaning costs increase as conversations grow longer
- Artifact mode: Creating artifacts is more token-efficient for long-form content because it focuses processing on the specific content being created rather than the entire conversation history
- Strategic implications: For drafting long documents, using artifacts instead of chat can be more efficient and cost-effective
💡 TIP: For document creation tasks over 1,000 words, switch to artifacts rather than chat. This can reduce token consumption by up to 70% for the same output, as the AI doesn’t need to reprocess the entire conversation history with each message.
Comparing Context Windows Across Platforms
| Platform | Context Window (tokens) | Word Equivalent (approx.) | Lost in Middle Effect |
|---|---|---|---|
| Claude 3.5 Sonnet | 200,000 | 150,000 | Minimal |
| Claude Enterprise | 500,000 | 375,000 | Minimal |
| GPT-4o | 128,000 | 96,000 | Moderate |
| GPT-3.5 | 16,385 | 12,000 | Significant |
| Microsoft Copilot | 64,000 | 48,000 | Moderate |
| Google Gemini | 1,000,000+ | 750,000+ | Variable |
💡 TIP: When working with lengthy technical documentation or codebases, Claude’s 200,000 token window makes it the optimal choice. For general business tasks, GPT-4o’s 128,000 token window is usually sufficient and may offer faster response times.
Strategic Implementation Considerations
Message Limits vs. Token Limits
Business users need to understand the relationship between message counts and token usage:
- Claude Pro limits: The ~45 messages per 5 hours limit on Claude Pro is a message count, not a token count
- Message size impact: A single 5,000-word document upload counts as one message but consumes thousands of tokens
- Conversation growth: As conversations progress, each message processes more tokens due to the growing history
💡 TIP: For Claude Pro users, maximize your 45-message allowance by focusing on document analysis rather than back-and-forth chatting. A single message with a large document upload and specific instructions will deliver more value than multiple short exchanges.
Optimizing Token Usage for Business Applications
- Strategic conversation resets: Start new conversations for different topics to reduce token overhead
- Document preprocessing: Extract only relevant sections of large documents before uploading
- Response length management: Request concise answers when detailed responses aren’t necessary
- Conversation pruning: For ongoing projects, periodically summarize important points and start fresh
💡 TIP: When sharing documents with AI, remove unnecessary elements like headers, footers, and repetitive boilerplate text. For a 20-page contract, this preprocessing could save 500-1,000 tokens that would otherwise be wasted on non-essential content.
Multi-Modal Efficiency
When working with images, audio, or video:
- Image tokens: Visual inputs consume tokens differently than text (often at much higher rates)
- Image resolution tradeoffs: Higher resolution images consume more tokens
- Video frames: Processing video consumes tokens for each frame analyzed
💡 TIP: For image processing with AI models, resize images to 768-1024px on the longest edge before uploading. This resolution provides sufficient detail for most analysis tasks while significantly reducing token consumption compared to higher resolutions. For document scans specifically, maintain 300 DPI but crop to just the content area.
Advanced Token Strategies for Developers
Prompt Engineering for Token Efficiency
- Instruction clarity: Clear, concise instructions reduce token waste
- Example selection: Providing one excellent example is often more token-efficient than multiple mediocre examples
- Few-shot learning: Strategically placing examples can improve performance while minimizing token usage
💡 TIP: Structure complex prompts using clear section headers and bullet points rather than long paragraphs. This formatting makes it easier for the AI to parse the information and often reduces the tokens needed for it to understand and follow your instructions.
API Integration Best Practices
- Token estimation: Pre-calculating approximate token counts can help manage costs
- Stream processing: For long outputs, using streaming responses can improve user experience
- Parallel processing: Breaking large documents into smaller chunks that can be processed in parallel
- Caching strategies: Storing and reusing responses for common queries
💡 TIP: When building applications that integrate with AI APIs, implement a client-side caching mechanism for frequent queries. This can reduce token consumption by 30-50% for common interactions while improving response times for users.
Conclusion: The Future of AI, Tokens and Context Windows
As AI models continue to evolve, we’re seeing rapid expansion of context window capabilities. Recent advancements suggest that the technical limitations of context windows may continue to expand:
- Specialized architectures: New AI architectures specifically designed for processing extremely long contexts
- Hybrid retrieval systems: Combining large context windows with efficient retrieval mechanisms
- Adaptive attention: More sophisticated attention mechanisms that can focus on relevant information regardless of position
For businesses leveraging AI, understanding these technical foundations helps in making strategic decisions about which platforms to use for different tasks and how to optimize workflows for cost-efficiency without sacrificing performance.
💡 TIP: Courtesy Costs Tokens—but It Can Boost Results
While polite language like “please,” “thank you,” and friendly tone markers aren’t necessary for AI to function, they do consume extra tokens. That said, maintaining courtesy in your prompts often leads to more thoughtful, balanced, and helpful AI responses.
A positive tone can subtly influence the AI’s “thought process,” promoting more fulfilling conversations—especially for creative work, strategic brainstorming, or sensitive topics.Coaching advice: If you’re working on something where tone and quality matter more than pure token efficiency, don’t be afraid to be polite. It’s a small investment that can pay off in better engagement and richer outputs.
Conclusion: The Future of Context Windows
As AI models continue to evolve, we’re seeing rapid expansion of context window capabilities.
Specialized architectures, hybrid retrieval systems, and adaptive attention mechanisms are pushing the boundaries of what AI can process and remember.
For technical leaders and innovators, understanding these foundations now gives you an important advantage:
Choosing the right tools, structuring your workflows for efficiency, and making smart, cost-effective decisions about how you apply AI in the real world.
✨ Let’s Build Together
Curious about how to apply these concepts to a real-world project?
Whether you’re designing your first AI-driven workflow, optimizing your current systems, or exploring large-context AI solutions — we’re here to help.
👉 Contact us today to explore how we can collaborate on your first—or your next—AI initiative.
💬 Join the Conversation
What questions do you still have about tokens, context windows, or AI optimization?
Drop a comment below or share your experiences working with token limits, large documents, or multi-modal AI.
Let’s keep the conversation going—and grow together!
Dan Stolts is the Chief Innovation Officer at jIT Solutions, where he helps business leaders navigate the complex landscape of emerging technologies and develop strategies for sustainable digital transformation.